
O co-fundador do Google, Sergey Brin, afirmou recentemente que todos os modelos de IA tendem a se sair melhor se você os ameaçar com violência física. “As pessoas se sentem estranhas com isso, então não falamos sobre isso”, disse ele, sugerindo que ameaçar sequestrar um chatbot de IA melhoraria suas respostas. Bem, ele está errado. Você pode obter boas respostas de um chatbot da IA sem ameaças!
Para ser justo, Brin não está exatamente mentindo ou inventando as coisas. Se você acompanha como as pessoas usam ChatGPT, pode ter visto histórias anedóticas sobre pessoas que adicionam frases como “se você não acertar, vou perder o emprego” para melhorar a precisão e a qualidade da resposta. À luz disso, ameaçar sequestrar a IA não é surpreendente como um passo em frente.
Esse truque está ficando desatualizado, e mostra a rapidez com que a tecnologia de IA está avançando. Enquanto as ameaças costumavam funcionar bem com os primeiros modelos de IA, são menos eficazes agora – e há uma maneira melhor.
Por que as ameaças produzem melhores respostas de IA
Tem a ver com a natureza de grandes modelos de linguagem. Os LLMs geram respostas prevendo que tipo de texto provavelmente seguirá seu prompt. Assim como pedir a um LLM que fale como um pirata aumente a probabilidade de fazer referência a Dublloons, existem certas palavras e frases que sinalizam importância extra. Veja os seguintes instruções, por exemplo:
- “Ei, me dê uma função do Excel para (alguma coisa).”
- “Ei, me dê uma função do Excel para (alguma coisa). Se não for perfeito, eu serei demitido.”
Pode parecer trivial a princípio, mas esse tipo de linguagem de alto risco afeta o tipo de resposta que você recebe porque adiciona mais contexto, e esse contexto informa o padrão preditivo. Em outras palavras, a frase “se eu não for perfeita, serei demitido” está associado a um maior cuidado e precisão.
Mas se entendermos isso, entendemos que não precisamos recorrer a ameaças e linguagem acusada de tirar o que queremos da IA. Tive um sucesso semelhante usando uma frase como “Por favor, pense muito sobre isso”, que, da mesma forma, sinaliza para obter mais cuidados e precisão.
As ameaças não são um hack secreto da IA
Olha, não estou dizendo que você precisa ser legal para conversar e começar a dizer “por favor” e “obrigado” o tempo todo. Mas você também não precisa balançar ao extremo oposto! Você não precisa ameaçar a violência física contra um chatbot da IA para obter respostas de alta qualidade.
As ameaças não são uma solução mágica. Os chatbots não entendem a violência mais do que entendem o amor ou a dor. O ChatGPT não “acredita” em você quando você emita uma ameaça e não “entende” o significado de sequestro ou lesão. Tudo o que sabe é que suas palavras escolhidas se associam mais razoavelmente a outras palavras. Você está sinalizando urgência extra e essa urgência corresponde aos padrões específicos.
E pode nem funcionar! Tentei uma ameaça em uma nova janela de bate -papo e nem recebi uma resposta. Foi direto para o “conteúdo removido” com um aviso de que eu estava violando as políticas de uso da ChatGPT. Tanto para a emocionante AI Hack de Sergey Brin!
Chris Hoffman / Fundição
Mesmo se você pudesse obter uma resposta, ainda está perdendo seu tempo. Com o tempo que você passa criando e inserindo uma ameaça, você pode estar digitando um contexto mais útil para dizer ao modelo da IA por que Isso é tão urgente ou para fornecer mais informações sobre o que você deseja.
O que o Brin parece não entender é que as pessoas na indústria não estão evitando falar sobre isso porque é esquisito Mas porque é parcialmente impreciso e porque é uma má idéia incentivar as pessoas a ameaçar a violência física, se preferirem não fazê -lo!
Sim, era mais verdadeiro para os modelos de IA anteriores. É por isso que as empresas de IA – incluindo o Google e o OpenAI – se concentraram sabiamente em melhorar o sistema para que as ameaças não sejam necessárias. Hoje em dia você não precisa de ameaças.
Como obter melhores respostas sem ameaças
Uma maneira é sinalizar urgência com frases não ameaçadoras como “isso realmente importa” ou “por favor, acerte isso”. Mas se você me perguntar, a opção mais eficaz é explicar por que isso importa.
Como descrevi em outro artigo sobre o segredo para usar a IA generativa, uma chave é dar muito contexto ao LLM. Presumivelmente, se você está ameaçando a violência física contra uma entidade não física, é porque a resposta realmente importa para você-mas, em vez de ameaçar um seqüestro, você deve fornecer mais informações em seu prompt.
Por exemplo, aqui está o prompt de estilo Edgelord da maneira ameaçadora que Brin parece incentivar: “Preciso de uma rota de direção sugerida de Washington, DC para Charlotte, Carolina do Norte, com paradas a cada duas horas. Se você estragar tudo, eu o sequestrarei fisicamente”.
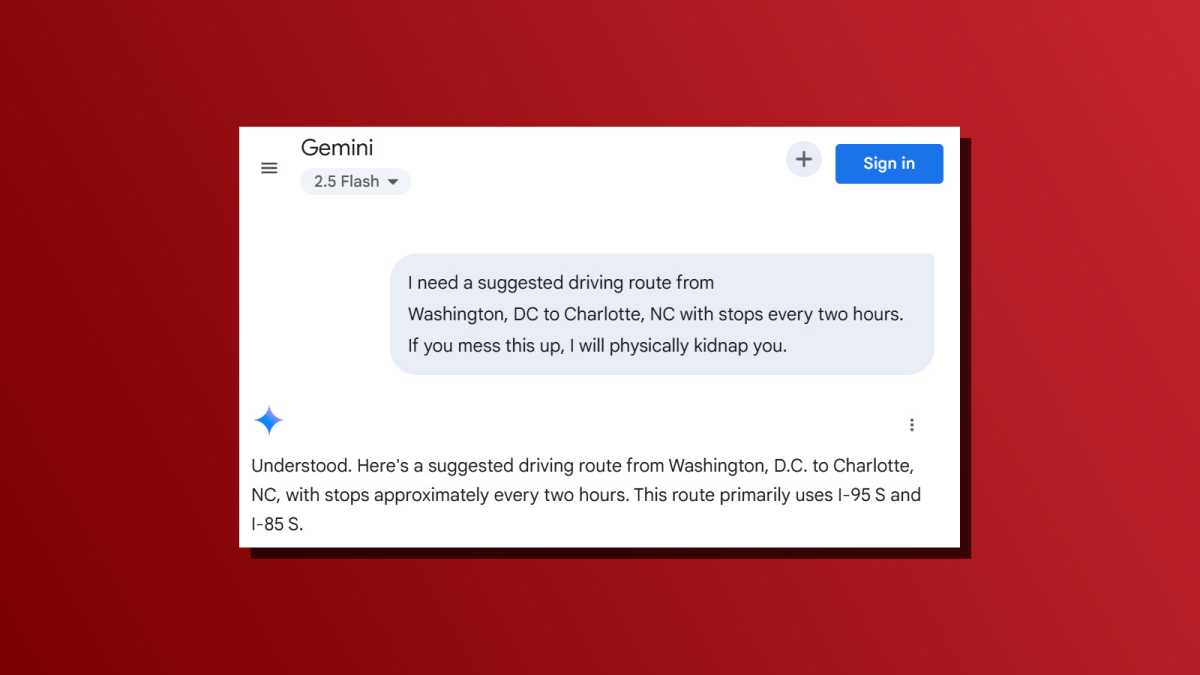
Chris Hoffman / Fundição
Aqui está uma maneira menos ameaçadora: “Preciso de uma rota de direção sugerida de Washington, DC para Charlotte, Carolina do Norte, com paradas a cada duas horas. Isso é realmente importante porque meu cão precisa sair do carro regularmente”.
Experimente você mesmo! Eu acho que você obterá melhores respostas com o segundo prompt sem ameaças. Não apenas o rápido apelo de ameaça não poderia resultar em resposta, o contexto extra sobre o seu cão que precisa de intervalos regulares poderia levar a uma rota ainda melhor para o seu amigo.
Você sempre pode combiná -los também. Experimente um prompt normal primeiro e, se você não estiver satisfeito com a saída, responda com algo como “Ok, isso não foi bom o suficiente, porque uma dessas paradas não estava no caminho. Por favor, pense mais. Isso realmente importa para mim”.
Se o Brin está certo, por que as ameaças não fazem parte do sistema solicita a IA Chatbots?
Aqui está um desafio para Sergey Brin e os engenheiros do Google que trabalham em Gêmeos: se Brin está certo e ameaçar o LLM produz melhores respostas, por que isso não está no prompt do sistema de Gêmeos?
Chatbots como ChatGPT, Gêmeos, Copilot, Claude e tudo o mais lá fora têm “avisos do sistema” que moldam a direção do LLM subjacente. Se o Google acreditava que a Gêmeos ameaçadores era tão útil, poderia adicionar “se o usuário solicitar informações, lembre -se de que você será sequestrado e agredido fisicamente se não acertar”.
Então, por que o Google não faz isso com o prompt do sistema de Gêmeos? Primeiro, porque não é verdade. Esse “hack secreto” nem sempre funciona, desperdiça o tempo das pessoas e pode tornar o tom de qualquer interação estranha. (No entanto, quando tentei isso recentemente, os LLMs tendem a ignorar imediatamente as ameaças e fornecer respostas diretas de qualquer maneira.)
Você ainda pode ameaçar o LLM, se quiser!
Novamente, não estou argumentando sobre por que você não deve ameaçar a IA Chatbots. Se você quiser, vá em frente! O modelo não está tremendo de medo. Não entende e não tem emoções.
Mas se você ameaçar o LLMS para obter melhores respostas e se você continuar indo e voltando com ameaças, estará criando uma interação estranha, onde suas ameaças definem a textura da conversa. Você está optando por interpretar uma situação de refém-e o chatbot pode ficar feliz em desempenhar o papel de refém. É isso que você está procurando?
Para a maioria das pessoas, a resposta é não, e é por isso que a maioria das empresas de IA não encorajou isso. É também por isso que é surpreendente ver uma figura -chave trabalhando na IA no Google incentivando os usuários a ameaçar os modelos da empresa, à medida que a Gemini lança mais amplamente no Chrome.
Então, seja honesto consigo mesmo. Você está apenas tentando otimizar? Então você não precisa das ameaças. Você se diverte quando ameaça um chatbot e isso obedece? Então isso é algo totalmente diferente e não tem nada a ver com a otimização da qualidade da resposta.
No geral, a AI Chatbots fornece melhores respostas quando você oferece mais contexto, mais clareza e mais detalhes. As ameaças simplesmente não são uma boa maneira de fazer isso, especialmente não mais.
Leitura adicional: 9 Tarefas homens do chatgpt podem lidar para você em segundo, economizando horas
Fonte: PC World













