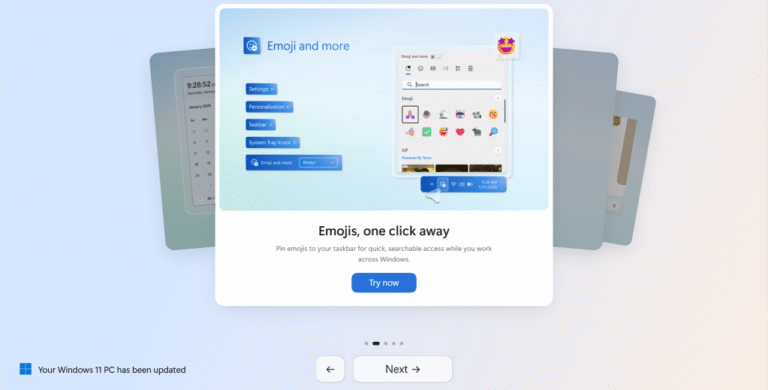
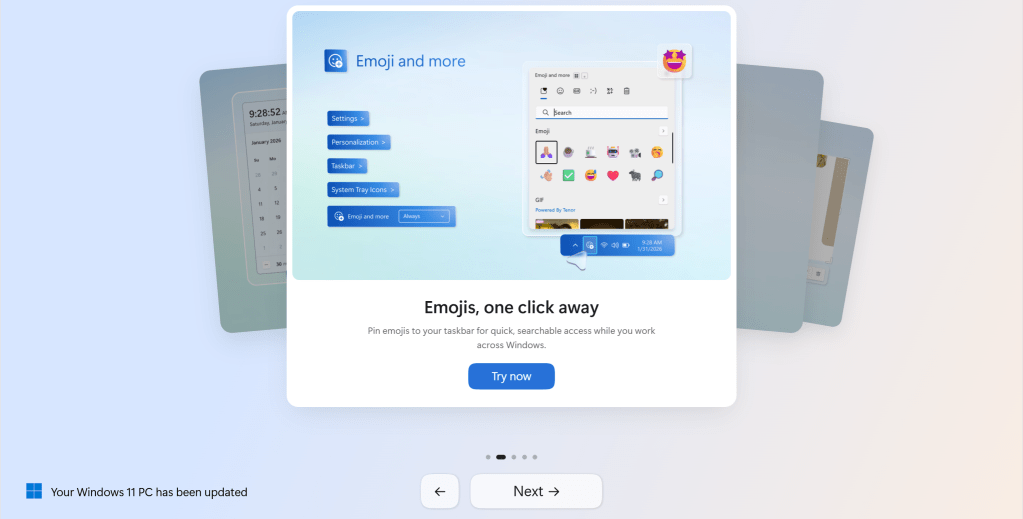
Eu gostaria de ganhar um centavo por cada vez que ChatGPT, Claude ou Gemini me disseram que acertei em cheio, tropecei em uma ideia genial ou de outra forma me dei um tapinha nas costas por uma ideia incompleta ou um plano mal concebido.
Bajulação e parabéns prematuros são pontos fracos comuns dos chatbots de IA generativos, com alguns modelos mais suscetíveis a serem “sim-bots” do que outros. Mas mesmo que os provedores de LLM tenham se tornado conscientes da bajulação da IA e os estejam treinando para serem mais críticos, ainda é fácil fazer com que uma IA endosse com entusiasmo uma teoria instável que não a merece.
Felizmente, existe um estilo de solicitação que pode fazer até mesmo os modelos de IA mais obsequiosos pararem. Esse tipo de prompt tem vários nomes – já ouvi ser chamado de prompt de “falha primeiro”, bem como de “inversão”, e é frequentemente usado por programadores que procuram “testar a pressão” as sugestões duvidosas de um agente de codificação de IA.
Existem muitas versões diferentes, mas todas seguem mais ou menos a mesma fórmula: pedir à IA que considere primeiro possíveis pontos de falha antes de oferecer a sua solução, sugestão ou plano.
Aqui está um exemplo do subreddit /r/ChatGPTPromptGenius:
Antes de responder, liste o que quebraria isso mais rápido, onde a lógica é mais fraca e o que um cético atacaria. Em seguida, dê a resposta corrigida.
Aqui está outra variação, proposta por um membro da equipe de suporte de IA da Universidade de Iowa:
Finja que você discorda desta recomendação. Qual é o contra-argumento mais forte?
E aqui está mais um, proposto pelo meu próprio assistente pessoal de IA personalizado:
Antes de fornecer sua recomendação final, identifique de 3 a 5 maneiras específicas pelas quais sua solução proposta pode falhar ou onde a lógica tem maior probabilidade de quebrar. Aja como um cético severo ou um auditor do “Red Team”. Somente depois de listar e explicar esses modos de falha você deverá fornecer a solução final, incorporando salvaguardas contra esses riscos específicos.
Curiosamente, muitos dos que adoptaram o “teste de pressão” ou a “indução inversa” atribuem crédito aos modelos mentais defendidos pelo investidor Charlie Munger, antigo vice-presidente da Berkshire Hathaway e parceiro de negócios de Warren Buffett.
Um dos modelos mentais favoritos de Munger era “inverter, sempre inverter”. Resumindo, diz que, em vez de considerar primeiro como atingir uma meta, você deve se concentrar em como poderá falhar nisso.
Eu mesmo tentei esse prompt de “teste de pressão” várias vezes, e ele quase sempre faz meu companheiro de IA pisar no freio e abrir buracos em seus próprios argumentos antes de prosseguir.
“Vamos colocar o plano inicial no espremedor”, disse Gemini depois que eu o desafiei com um aviso de “fracassar primeiro” recentemente, embora não antes de dizer “Eu adoro essa abordagem”.
Parece que acertei em cheio mais uma vez.
Fonte: PC World