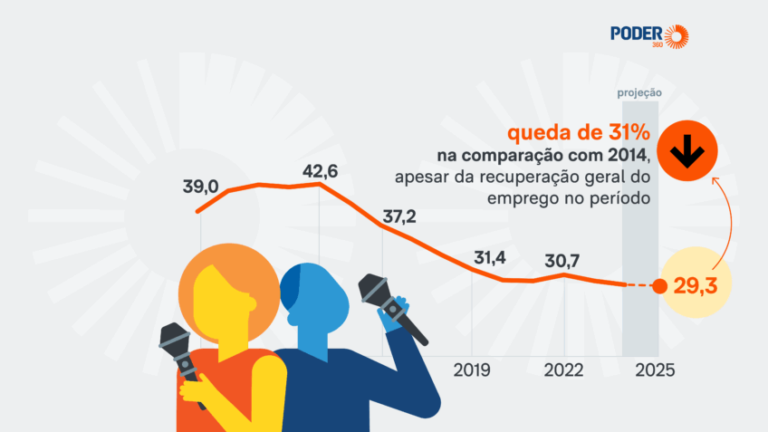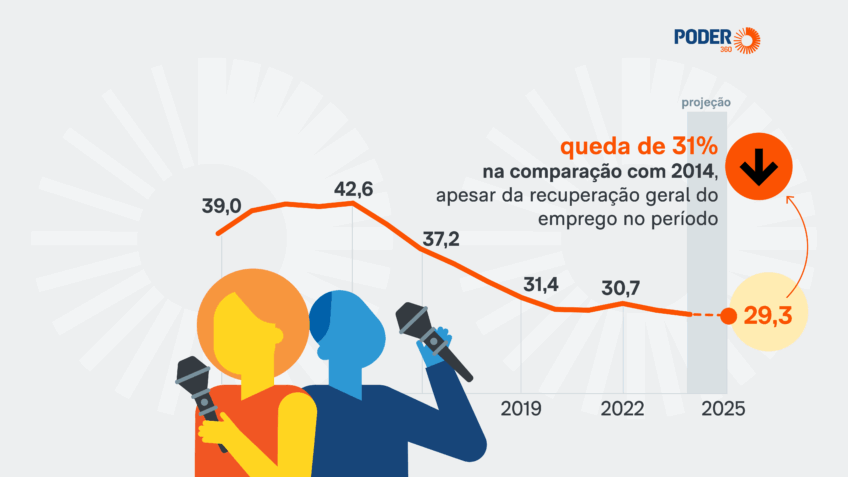
A Enciclopédia Britânica e sua subsidiária Merriam-Webster processaram a OpenAI, alegando que a empresa de IA generativa (genAI) usou seus textos de enciclopédia e dicionário para treinar modelos de IA como ChatGPT sem permissão, de acordo com a Reuters.
O processo alega que a OpenAI copiou quase 100.000 artigos do material da Britannica e afirma que o ChatGPT pode reproduzir conteúdo quase literalmente, o que corre o risco de reduzir o tráfego online para seus próprios sites.
A Britannica também acusou a OpenAI de violação de marca registrada, já que as respostas da IA às vezes fazem referência à Britannica de uma forma que pode dar a impressão de que o material está sendo usado com permissão. A empresa agora busca uma compensação financeira e quer que o tribunal interrompa o suposto uso de seu material.
Fonte: Computer World